Monday, 12 April 2021
08:46 PM
The amoral nonsense of Orchid’s embryo selection [Bits of DNA] 08:46 PM, Monday, 12 April 2021 12:00 AM, Friday, 30 July 2021
If you haven’t heard about Clubhouse yet… well, it’s the latest Silicon Valley unicorn, and the popular new chat hole for thought leaders. I heard about it for the first time a few months ago, and was kindly offered an invitation (Club house is invitation only!) so I could explore what it is all about. Clubhouse is an app for audio based social networking, and the content is, as far as I can tell, a mixed bag. I’ve listened to a handful of conversations hosted on the app.. topics include everything from bitcoin to Miami. It was interesting, at times, to hear the thoughts and opinions of some of the discussants. On the other hand, there is a lot of superficial rambling on Clubhouse as well. During a conversation about genetics I heard someone posit that biology has a lot to learn from the fashion industry. This was delivered in a “you are hearing something profound” manner, by someone who clearly knew nothing about either biology or the fashion industry, which is really too bad, because the fashion industry is quite interesting and I wouldn’t be surprised at all if biology has something to learn from it. Unfortunately, I never learned what that is.
One of the regulars on Clubhouse is Noor Siddiqui. You may not have heard of her; in fact she is officially “not notable”. That is to say, she used to have a Wikipedia page but it was deleted on the grounds that there is nothing about her that indicates notability, which is of course notable in and of itself… a paradox that says more about Wikipedia’s gatekeeping than Siddiqui (Russell 1903, Litt 2021). In any case, Siddiqui was recently part of a Clubhouse conversation on “convergence of genomics and reproductive technology” together with Carlos Bustamante (advisor to cryptocurrency based Luna DNA and soon to be professor of business technology at the University of Miami) and Balaji Srinivasan (bitcoin angel investor and entrepreneur). As it happens, Siddiqui is the CEO of a startup called “Orchid Health“, in the genomics and reproductive technology “space”. The company promises to harness “population genetics, statistical modeling, reproductive technologies, and the latest advances in genomic science” to “give parents the option to lower a future child’s genetic risk by creating embryos through in IVF and implanting embryos in the order that can reduce disease risk.” This “product” will be available later this year. Bustamante and Srinivasan are early “operators and investors” in the venture.
Orchid is not Siddiqui’s first startup. While she doesn’t have a Wikipedia page, she does have a website where she boasts of having (briefly) been a Thiel fellow and, together with her sister, starting a company as a teenager. The idea of the (briefly in existence) startup was apparently to help the now commercially defunct Google Glass gain acceptance by bringing the device to the medical industry. According to Siddiqui, Orchid is also not her first dive into statistical modeling or genomics. She notes on her website that she did “AI and genomics research”, specifically on “deep learning for genomics”. Such training and experience could have been put to good use but…
Polygenic risk scores and polygenic embryo selection
Orchid Health claims that it will “safely and naturally, protect your baby from diseases that run in your family” (the slogan “have healthy babies” is prominently displayed on the company’s website). The way it will do this is to utilize “advances in machine learning and artificial intelligence” to screen embryos created through in-vitro fertilization (IVF) for “breast cancer, prostate cancer, heart disease, atrial fibrillation, stroke, type 2 diabetes, type 1 diabetes, inflammatory bowel disease, schizophrenia and Alzheimer’s“. What this means in (a statistical geneticist’s) layman’s terms is that Orchid is planning to use polygenic risk scores derived from genome-wide association studies to perform polygenic embryo selection for complex diseases. This can be easily unpacked because it’s quite a simple proposition, although it’s far from a trivial one- the statistical genetics involved is deep and complicated.
First, a single-gene disorder is a health problem that is caused by a single mutation in the genome. Examples of such disorders include Tay-Sachs disease, sickle cell anaemia, Huntington’s disease, Duchenne muscular dystrophy, and many other diseases. A “complex disease”, also called a multifactorial disease, is a disease that has a genetic component, but one that involves multiple genes, i.e. it is not a single-gene disorder. Crucially, complex diseases may involve effects of environmental factors, whose role in causing disease may depend on the genetic composition of an individual. The list of diseases on Orchid’s website, including breast cancer, prostate cancer, heart disease, atrial fibrillation, stroke, type 2 diabetes, type 1 diabetes, inflammatory bowel disease, schizophrenia and Alzheimer’s disease are all examples of complex (multifactorial) diseases.
To identify genes that associate with a complex disease, researchers perform genome-wide association studies (GWAS). In such studies, researchers typically analyze several million genomic sites in a large numbers of individuals with and without a disease (used to be thousands of individuals, nowadays hundreds of thousands or millions) and perform regressions to assess the marginal effect at each locus. I italicized the word associate above, because genome-wide association studies do not, in and of themselves, point to genomic loci that cause disease. Rather, they produce, as output, lists of genomic loci that have varying degrees of association with the disease or trait of interest.
Polygenic risk scores
(PRS), which the Broad Institute
claims to have discovered (narrator: they were not discovered
at the Broad Institute), are a way to combine the multiple genetic
loci associated with a complex disease from a GWAS. Specifically, a
PRS 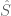
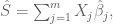
where the sum is over 
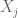
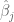
While much of the discussion around PRS applications centers on applications such as determining diagnostic testing frequency (Wald and Old 2019), polygenic embryo selection (PES) posits that polygenic risk scores should be taken a step further and evaluated for embryos to be used as a basis for discarding, or selecting, specific embryos for in vitro fertilization implantation. The idea has been widely criticized and critiqued (Karavani et al. 2019). It has been described as unethical, morally repugnant, and concerns about its use for eugenics have been voiced by many. Underlying these criticisms is the fact that the technical issues with PES using PRS are manifold.
Poor penetrance
The term “penetrance” for a disease refers to the proportion of individuals with a particular genetic variant that have the disease. Many single-gene disorders have very high penetrance. For example, F508del mutation in the CFTR gene is 100% penetrant for cystic fibrosis. That is, 100% of people who are homozygous for this variant, meaning that both copies of their DNA have a deletion of the phenylalanine amino acid in position 508 of their CFTR gene, will have cystic fibrosis. The vast majority of variants associated with complex diseases have very low penetrance. For example, in schizophrenia, the penetrance of “high risk” de novo copy number variants (in which there are variable copies of DNA at a genomic loci) was found to be between 2% and 7.4% (Vassos et al 2010). The low penetrance at large numbers of variants for complex diseases was precisely the rationale for developing polygenic risk scores in the first place, the idea being that while individual variants yield small effects, perhaps in (linear) combination they can have more predictive power. While it is true that combining variants does yield more predictive power for complex diseases, unfortunately the accuracy is, in absolute terms, very low.
The reason for low predictive power of PRS is explained well in (Wald and Old 2020) and is illustrated for coronary artery disease (CAD) in (Rotter and Lin 2020):

The issue is that while the polygenic risk score distribution may indeed be shifted for individuals with a disease, and while this shift may be statistically significant resulting in large odds ratios, i.e. much higher relative risk for individuals with higher PRS, the proportion of individuals in the tail of the distributions who will or won’t develop the disease will greatly affect the predictive power of the PRS. For example, Wald and Old note that PRS for CAD from (Khera et al. 2018) will confer a detection rate of only 15% with a false positive rate of 5%. At a 3% false positive rate the detection rate would be only 10%. This is visible in the figure above, where it is clear that control of the false positive right (i.e. thresholding at the extreme right-hand side with high PRS score) will filter out many (most) affected individuals. The same issue is raised in the excellent review on PES of (Lázaro-Muńoz et al. 2020). The authors explain that “even if a PRS in the top decile for schizophrenia conferred a nearly fivefold increased risk for a given embryo, this would still yield a >95% chance of not developing the disorder.” It is worth noting in this context, that diseases like schizophrenia are not even well defined phenotypically (Mølstrøm et al. 2020), which is another complex matter that is too involved to go into detail here.
In a recent tweet, Siddiqui describes natural conception as a genetic lottery, and suggests that Orchid Health, by performing PES, can tilt the odds in customers’ favor. To do so the false positive rate must be low, or else too many embryos will be discarded. But a 15% sensitivity is highly problematic considering the risks inherent with IVF in the first place (Kamphuis et al. 2014):

To be concrete, an odds ratio of 2.8 for cerebral palsy needs to be balanced against the fact that in the Khera et al. study, only 8% of individuals had an odds ratio >3.0 for CAD. Other diseases are even worse, in this sense, than CAD. In atrial fibrillation (one of the diseases on Orchid Health’s list), only 9.3% of the individuals in the top 0.44% of the atrial fibrillation PRS actually had atrial fibrillation (Choi et al 2019).As one starts to think carefully about the practical aspects and tradeoffs in performing PES, other issues, resulting from the low penetrance of complex disease variants, come into play as well. (Lencz et al. 2020) examine these tradeoffs in detail, and conclude that “the differential performance of PES across selection strategies and risk reduction metrics may be difficult to communicate to couples seeking assisted reproductive technologies… These difficulties are expected to exacerbate the already profound ethical issues raised by PES… which include stigmatization, autonomy (including “choice overload”, and equity. In addition, the ever-present specter of eugenics may be especially salient in the context of the LRP (lowest-risk prioritization) strategy.” They go on to “call for urgent deliberations amongst key stakeholders (including researchers, clinicians, and patients) to address governance of PES and for the development of policy statements by professional societies.”
Pleiotropy predicaments
I remember a conversation I had with Nicolas Bray several years ago shortly after the exciting discovery of CRISPR/Cas9 for genome editing, on the implications of the technology for improving human health. Nick pointed out that the development of genomics had been curiously “backwards”. Thirty years ago, when human genome sequencing was beginning in earnest, the hope was that with the sequence at hand we would be able to start figuring out the function of genes, and even individual base pairs in the genome. At the time, the human genome project was billed as being able to “help scientists search for genes associated with human disease” and it was imagined that “greater understanding of the genetic errors that cause disease should pave the way for new strategies in diagnosis, therapy, and disease prevention.” Instead, what happened is that genome editing technology has arrived well before we have any idea of what the vast majority of the genome does, let alone the implications of edits to it. Similarly, while the coupling of IVF and genome sequencing makes it possible to select embryos based on genetic variants today, the reality is that we have no idea how the genome functions, or what the vast majority of genes or variants actually do.
One thing that is known about the genome is that it is chock full of pleiotropy. This is statistical genetics jargon for the fact that variation at a single locus in the genome can affect many traits simultaneously. Whereas one might think naïvely that there are distinct genes affecting individual traits, in reality the genome is a complex web of interactions among its constituent parts, leading to extensive pleiotropy. In some cases pleiotropy can be antagonistic, which means that a genomic variant may simultaneously be harmful and beneficial. A famous example of this is the mutation to the beta globin gene that confers malaria resistance to heterozygotes (individuals with just one of their DNA copies carrying the mutation) and sickle cell anemia to homozygotes (individuals with both copies of their DNA carrying the mutation).
In the case of complex diseases we don’t really know enough, or anything, about the genome to be able to truly assess pleiotropy risks (or benefits). But there are some worries already. For example, HLA Class II genes are associated with Type I and non-insulin treated Type 2 diabetes (Jacobi et al 2020), Parkinson’s disease (e.g. James and Georgopolous 2020, which also describes an association with dementia) and Alzheimer’s (Wang and Xing 2020). PES that results in selection against the variants associated with these diseases could very well lead to population susceptibility to infectious disease. Having said that, it is worth repeating that we don’t really know if the danger is serious, because we don’t have any idea what the vast majority of the genome does, nor the nature of antagonistic pleiotropy present in it. Almost certainly by selecting for one trait according to PRS, embryos will also be selected for a host of other unknown traits.
Thus, what can be said is that while Orchid Health is trying to convince potential customers to not “roll the dice“, by ignoring the complexities of pleiotropy and its implications for embryo selection, what the company is actually doing is in fact rolling the dice for its customers (for a fee).

Population problems
One of Orchid Health’s selling points is that unlike other tests that “look at 2% of only one partner’s genome…Orchid sequences 100% of both partner’s genomes” resulting in “6 billion data points”. This refers to the “couples report”, which is a companion product of sorts to the polygenic embryo screening. The couples report is assembled by using the sequenced genomes of parents to simulate the genomes of potential babies, each of which is evaluated for PRS’ to provide a range of (PRS based) disease predictions for the couples potential children. Sequencing a whole genome is a lot more expensive that just assessing single nucleotide polymorphisms (SNPs) in a panel. That may be one reason that most direct-to-consumer genetics is based on polymorphism panels rather than sequencing. There is another: the vast majority of variation in the genome occurs at a known polymorphic sites (there are a few million out of the approximately 3 billion base pairs in the genome), and to the extent that a variant might associate with a disease, it is likely that a neighboring common variant, which will be inherited together with the causal one, can serve as a proxy. There are rare variants that have been shown to associate with disease, but whether or not they explain can explain a large fraction of (genetic) disease burden is still an open question (Young 2019). So what has Siddiqui, who touts the benefits of whole-genome sequencing in a recent interview, discovered that others such as 23andme have missed?
It turns out there is value to whole-genome sequencing for polygenic risk score analysis, but it is when one is performing the genome-wide association studies on which the PRS are based. The reason is a bit subtle, and has to do with differences in genetics between populations. Specifically, as explained in (De La Vega and Bustamante, 2018), variants that associate with a disease in one population may be different than variants that associate with the disease in another population, and whole-genome sequencing across populations can help to mitigate biases that result when restricting to SNP panels. Unfortunately, as De La Vega and Bustamante note, whole-genome sequencing for GWAS “would increase costs by orders of magnitude”. In any case, the value of whole-genome sequencing for PRS lies mainly in identifying relevant variants, not in assessing risk in individuals.
The issue of population structure affecting PRS unfortunately transcends considerations about whole-genome sequencing. (Curtis 2018) shows that PRS for schizophrenia is more strongly associated with ancestry than with the disease. Specifically, he shows that “The PRS for schizophrenia varied significantly between ancestral groups and was much higher in African than European HapMap subjects. The mean difference between these groups was 10 times as high as the mean difference between European schizophrenia cases and controls. The distributions of scores for African and European subjects hardly overlapped.” The figure from Curtis’ paper showing the distribution of PRS for schizophrenia across populations is displayed below (the three letter codes at the bottom are abbreviations for different population groups; CEU stands for Northern Europeans from Utah and is the lowest).

The dependence of PRS on population is a problem that is compounded by a general problem with GWAS, namely that Europeans and individuals of European descent have been significantly oversampled in GWAS. Furthermore, even within a single ancestry group, the prediction accuracy of PRS can depend on confounding factors such as socio-economic status (Mostafavi et al. 2020). Practically speaking, the implications for PES are beyond troubling. The PRS scores in the reports customers of Orchid Health may be inaccurate or meaningless due to not only the genetic background or admixture of the parents involved, but also other unaccounted for factors. Embryo selection on the basis of such data becomes worse than just throwing dice, it can potentially lead to unintended consequences in the genomes of the selected embryos. (Martin et al. 2019) show unequivocally that clinical use of polygenic risk scores may exacerbate health disparities.
People pathos
The fact that Silicon Valley entrepreneurs are jumping aboard a technically incoherent venture and are willing to set aside serious ethical and moral concerns is not very surprising. See, e.g. Theranos, which was supported by its investors despite concerns being raised about the technical foundations of the company. After a critical story appeared in the Wall Street Journal, the company put out a statement that
“[Bad stories]…come along when you threaten to change things, seeded by entrenched interests that will do anything to prevent change, but in the end nothing will deter us from making our tests the best and of the highest integrity for the people we serve, and continuing to fight for transformative change in health care.”
While this did bother a few investors at the time, many stayed the course for a while longer. Siddiqui uses similar language, brushing off criticism by complaining about paternalism in the health care industry and gatekeeping, while stating that
“We’re in an age of seismic change in biotech – the ability to sequence genomes, the ability to edit genomes, and now the unprecedented ability to impact the health of a future child.”
Her investors, many of whom got rich from cryptocurrency trading or bitcoin, cheer her on. One of her investors is Brian Armstrong, CEO of Coinbase, who believes “[Orchid is] a step towards where we need to go in medicine.” I think I can understand some of the ego and money incentives of Silicon Valley that drive such sentiment. But one thing that disappoints me is that scientists I personally held in high regard, such as Jan Liphardt (associate professor of Bioengineering at Stanford) who is on the scientific advisory board and Carlos Bustamante (co-author of the paper about population structure associated biases in PRS mentioned above) who is an investor in Orchid Health, have associated themselves with the company. It’s also very disturbing that Anne Wojcicki, the CEO of 23andme whose team of statistical geneticists understand the subtleties of PRS, still went ahead and invested in the company.
Conclusion
Orchid Health’s polygenic embryo selection, which it will be offering later this year, is unethical and morally repugnant. My suggestion is to think twice before sending them three years of tax returns to try to get a discount on their product.

12:00 AM
R Weekly 2021-W15 reprex , Kubernetes, SQL in Rmarkdown [RWeekly.org - Blogs to Learn R from the Community] 12:00 AM, Monday, 12 April 2021 08:20 AM, Monday, 12 April 2021
Hello and welcome to this new issue!
This week’s release was curated by Colin Fay, with help from the R Weekly team members and contributors.
Highlight
Insights
R in the Real World
Resources
New Packages
CRAN

GitHub or Bitbucket
Updated Packages
Videos and Podcasts
Tutorials

-
A Deep Learning Classifier of New Testament Verse Authorship using the R Keras Package
-
Introducing Modeltime Recursive: Tidy Autoregressive Forecasting with Lags
-
Image segmentation in R: Automatic background removal like in a Zoom conference
R Project Updates
Updates from R Core:
Upcoming Events in 3 Months
Events in 3 Months:
Call for Participation
Quotes of the Week
This is a good time to spring clean your @github tokens:
— Jenny Bryan (@JennyBryan) April 5, 2021
* (re)generate to get the new format
* update how you make your token available to command line git and #rstats
gh 1.2.1 (new!) supports the new token format, so update that first!https://t.co/uvl8Eo5EFx https://t.co/QkVKDDvydS